How is it possible to build a tool for multiple languages without using a common IR? Why is Cubix the first framework that makes it possible to build source-to-source transformations for multiple languages without mutilating the code? How is it possible to add support for a new language in only 2 days?
Incremental parametric syntax is the key idea behind Cubix.
You wish to write a function which takes a program of language A to a program of language A, and a program of language B to a program of language B. What representation does it act on?
On the input side: The representation must include programs of both languages, so it must be more general than both (a common supertype, or coercible from a common supertype).
On the output side: Any value of this representation must be a valid program of both languages, meaning it must be more specific than either (a common subtype).
So, this "common representation" must be both a supertype and a subtype of both languages. This is only possible if language A and language B are the same language! Uh oh.
This is why the problem of multi-language source-to-source transformations had scarcely been attempted prior to Cubix, and why the only prior framework we've found in which this was possible had a tendency to convert all for-loops into while-loops.
The solution? Parametric syntax.
In parametric syntax, there is no common representation between languages. Instead, the language is given as a type parameter with various constraints, most commonly requiring that some common language fragment is present. A transformation can then be written on, e.g.: "any language that has assignments, blocks, and a name-binding analysis," with a type error given for languages that lack one of these.
![]()
The typical way to achieve modular syntax is to use some kind of modular datatype, which enables datatypes for multiple languagae definitions to be built from common components.
There are many approaches to modular data types, of which the three best known are: datatypes à la carte;
the tagless-final style; and their object-oriented equivalent, object algebras. The specific flavor used by Cubix is compositional datatypes, a descendant of datatypes à la carte with support for annotations,
holes in terms, and a type-safe representation of multiple sorts. In fact, the cubix-compdata library is a literal fork of Patrick Bahr's compdata
library from the Compositional Datatypes paper, with added functionality and a much more memory-efficient representation.
Parametric syntax is a new name for an old idea. But it's not enough...
Prior approaches to parametric syntax only scaled to toy languages and DSLs. Representing a real language required reconstructing an entire definition for that language from modular pieces. And that's hard, and often, the "identical pieces" between languages are just different enough that this does not work. (E.g.: assignments in different languages work differently regarding evaluation order, l-values, etc.)
After the creation of Cubix, Github's semantic team did attempt to scale the vanilla datatypes à la carte approach to multiple real languages. They eventually reverted to a more conventional representation (which is fine, as they only need to do analysis, not transformation).
However, most transformations only need to do with a fraction of a language's syntax. The key idea of incremental parametric syntax is to represent programs using a mixture of language-specific and generic parts. This makes it possible to add support for a language very quickly, by using an existing syntax-definition wholesale, and surgically replacing parts of it with generic nodes. Support for more of a language can then be incrementally added.
The enabling technology of IPS are sort injections. A sort injection is literally an injective function between sorts, i.e.: a sub-sorting relation. One example of a sort injection: the "assign" sort is a subsort of the "expression" sort in C. Another example: the "assign" sort is a subsort of the "statement" sort in Python.
By this mechanism, it is possible to create a generic assignment node, and customize it to take the exact syntactic place of the language's pre-existing assignment node.
Sort injections can be seen as the completion of modular datatypes. Approaches such as datatypes à la carte modularize the possible nodes in an AST. Sort injections further modularize the possible edges in an AST.
Yet sort injections can be easily implemented on top of modular datatypes: a sort injection from A to be is witnessed by a node of sort B whose child has sort A.

ASTs of an IPS are "mixed trees," containing both language-specific and generic nodes, with sort-injection nodes as the glue. For example, in the following picture, the light blue nodes on the left are Java-specific, the light purple assignment node on the right is a generic assignment, and the dark purple nodes in the middle are sort-injection nodes.
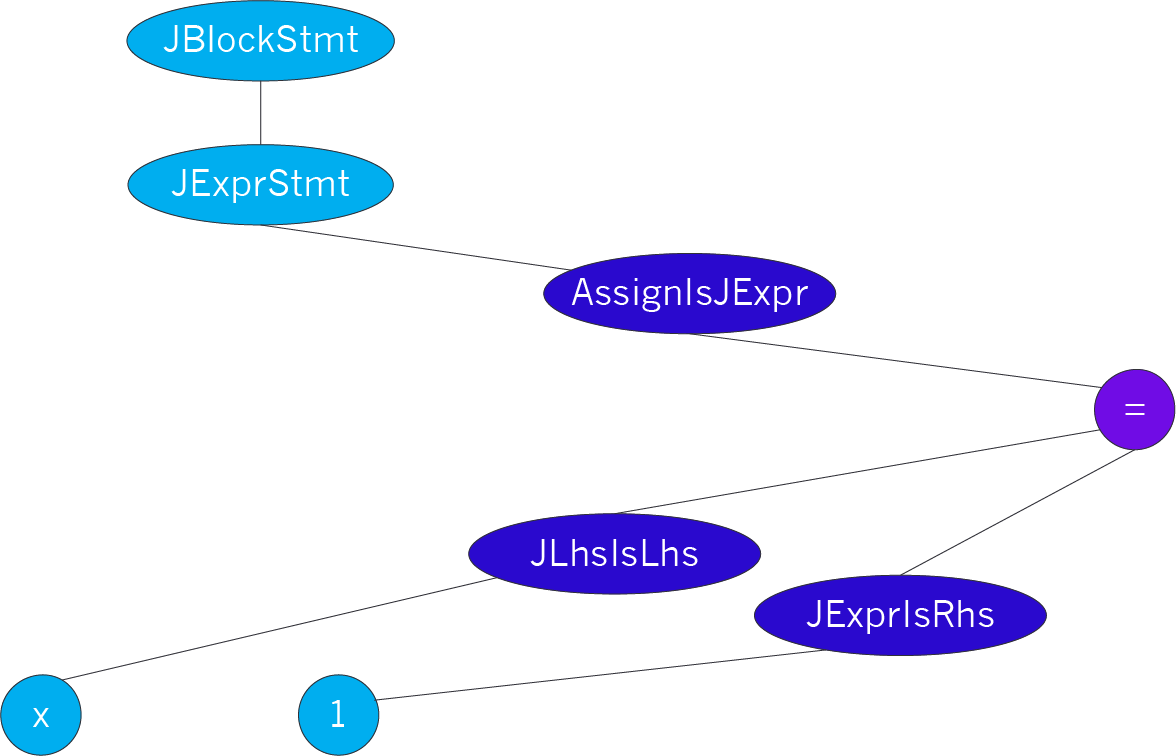
Sort injections may also be witnessed by a chain of pre-existing nodes. For example, in C, assignments may be used as C block statements (or Cubix's generic "block items"), and so the "assign" sort is a subset of the "block statement" sort in C. This inclusion is witnessed by a chain of intermediate expression and statement nodes. A transformation can work with the constraint "there is a sort injection from assign to block item," and thereby only work with generic assignment and block nodes, ignoring the C-specific intermediates.
![]()